Statistician / Machine Learning specialist
Benefits to clients:
-
One-stop-shop for complete data analysis cycle.
-
Simplified solution-oriented data analysis tools for complex nested messy datasets.
-
Quick dive into data sets of various domains, cleaning the noise from the signal, and discovering hidden insights.
-
Centralized multi-disciplinary expertise in solving complex data analysis problems, from first step of understanding the problem, designing the solution, arranging the data, providing the analytical solution, to delivering/communicating the results to various stakeholders across the organization, in terms that make sense to YOU!
Values:
-
Simplification: Simplify complex data structures / analytical pipelines / statistical concepts, into deliverable solutions.
-
Transparency: Open source tools, live progress update.
-
Communication: Frequent, continuous communication channels though all steps of work, from early scope definition, to final deliverable solutions.
-
Reproducibility: Stable results and fully documented steps, covering each step of the work.
-
Problem solving orientation: quick and simple proof-of-concept solutions to demonstrate scope of problem, and setting expectations for desired/possible solutions.
-
Reliability: continuous support on a project, with flexibility to scope extension. Tools are initially designed for high-level scope, reduce the need for a complete refactor.
Expertise:
Expand
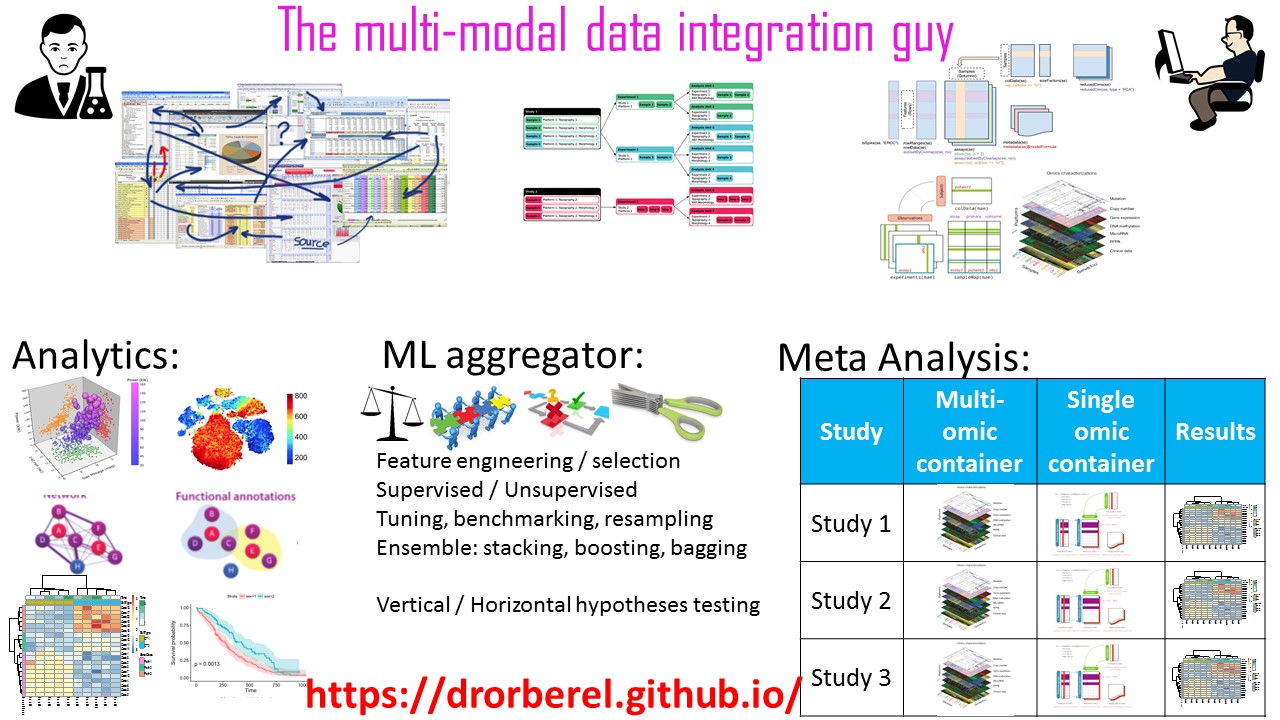
1. Designing analytical tools for complex data sets, of multiple sources / annotations.2. Data architecture: from complex messy raw data sets, to well-annotated 'tidy' nested data structure.
3. Visualization: Intuitive, user-customized graphics with dynamic adjustable controls, to allow self-exploration of data pattern and analytics sensitivity.
4. Statistical inference: Classic statistical multivariate tools, and machine learning.
5. Deliverable outcomes: HTML / PDF reproducible reports, Dynamic user activated Web-applications, APIs, etc.
6. Communicating the results to various stakeholders across the organization.
7. Addressing remaining potential gaps in current data/methodology, and suggesting next steps to bridge such gaps. Suggesting next steps for future hypothesis testing and experimental design.
Unique Solutions:
Expand
1. Fully reproducible analytical solutions, within a single programing environment (R), for both data architecture managements, analytics, and reporting.2. Free open-source tool. No dependencies on any external propriety software.
3. Advanced high-level programing style, reducing coding errors, and designed to better handle edge scenarios and debugging. (e.g. map-reduce, object-oriented data containers, 'tidy' workflow, ...).
4. Scalable tools for large data sets, sample replication, and additional data sets.
5. Implementation of up to date advanced statistical tools, from peer-reviewed scientific resources (Bioconductor, CRAN, etc.)
6. Supporting the entire process from formalizing the business questions, to data collection and wrangling, analytics, and reporting/communicating the results.
7. Aggregating results to higher level of meta-analysis.
Case Studies:
1. Multi-assay biomarker discovery.
Expand
Problem:Integrating complex datasets of various annotations to the same subjects. Each data set required specific QC and screening, and had different indexing system for the sample IDs. Also required special handling of technical replicates. Out of the thousands of potential biomarkers (features), find the ones that are mostly associated with the clinical outcome.
Solution:
Storing the raw data in a generic data container that was specifically designed for this type of data.
Vertical integration (concatenating) features from all assays into a 'long' format.
Designing a customized feature-selection process that combine univariate filtering, and unsupervised hierarchical clustering, followed by regularized regression, for biomarker discovery.
Wrapping the feature selection method under a generic Machine-Learning package, that facilitate tasks of resampling, tuning and benchmarking.
Resolution:
Scalable, custom-designed object-oriented data container is the ideal data structure for multi-modal data structure. Its built-in methods facilitate fast and simple common tasks for basic wrangling and reformatting.
Avoid re-inventing solutions that specialized packages were specifically designed for. Utilize Machine-Learning aggregator packages for common tasks of resampling, tuning, benchmarking etc.
Reference:
Peer-reviewed scientific paper is under review.
Github repo with complete reproducible analytic pipeline will be publicly accessible upon paper publication.
2. Utilizing Object oriented data containers for complex data structure.
Expand
Problem:Bioinformaticians developed customized scalable tools for handling complex large datasets for decades, even before industry faced similar dimensionality of data. However, because they demonstrate its use mostly for genomic data only, other industries are hesitant to benefit from it.
How to utilize and demonstrate that a constrained object oriented data structure, provide value to non-genomic data domains, of similar characteristics.
Solution:
Provide educational materials, and simple proof-of-concept demonstrations, on how these data containers can store non-genomic big data, emphasizing the advantages, and leverage of such approach.
Reference:
[https://medium.com/@drorberel/bioconductor-s4-classes-for-high-throughput-omic-data-fd6c304d569b](https://medium.com/@drorberel/bioconductor-s4-classes-for-high-throughput-omic-data-fd6c304d569b)